AI tools for audio restoration ai
Related Tools:
Boris FX
Boris FX is an award-winning AI-powered post-production tool that offers a comprehensive suite of products for film, video, photography, and audio editing. With a focus on VFX, tracking, masking, rotoscoping, 3D solving, and audio restoration, Boris FX provides a one-stop solution for content creators. The platform also features tutorials, premium training, live interviews, and community forums to support users in mastering their post-production tasks.

FlaiChat
FlaiChat is a superpowered chat application designed for multilingual families and close-knit groups. It is an AI-enhanced chat app that aims to bring families together by offering features such as an AI assistant (FlaiBot), location sharing, task assignment, chat restoration, and threaded conversations. Users can easily start chatting by scanning a code without the need for a phone number. FlaiChat prioritizes user data safety by encrypting data in transit and at rest on servers, although it does not utilize end-to-end encryption. The application is available on iOS and Android, with plans for desktop and web versions in the future.
Clip.audio
Clip.audio is an AI-powered audio search engine that allows users to search for and discover audio clips from a variety of sources, including podcasts, music, and sound effects. The platform uses advanced machine learning algorithms to analyze and index audio content, making it easy for users to find the specific audio clips they are looking for.
Fish Audio
Fish Audio is an AI-powered audio generation tool that allows users to convert text into speech. With a user-friendly interface, it offers a range of models for generating high-quality voices. Users can build their own voice models or use prebuilt ones, and collaborate with others. Backed by trusted partners, Fish Audio leverages Lepton AI's top models to provide a seamless experience for creating audio content.
Article.Audio
Article.Audio is a web application that allows users to convert articles into audio files, enabling them to listen to the content instead of reading it. Users can easily convert text documents, PDFs, and web links into audio format using natural-sounding human voices. The application offers a user-friendly interface and supports multiple languages and voice styles. Article.Audio is powered by Thundercontent and aims to provide a convenient and accessible way for users to consume written content on the go.

Kingshiper
Kingshiper is a versatile multimedia tool that offers a wide range of audio, photo, and video editing solutions. It provides users with tools for screen recording, video compression, audio editing, vocal removal, file conversion, and more. With a focus on simplicity and efficiency, Kingshiper aims to meet various multimedia processing needs, from creating professional videos to managing files and documents effortlessly. The software also includes utilities for office tasks, data recovery, system tools, and image processing, making it a comprehensive solution for multimedia and office-related tasks.
Guide.AI
Guide.AI is a platform that allows users to create and publish audio guides quickly and easily, using advanced AI text-to-speech and translation technology. Users can develop and distribute audio guides in multiple languages without the need for audio recordings or specialist equipment. The platform aims to enhance audience experience, boost income, accessibility, inclusivity, and engagement for guide authors and users alike.
LALAL.AI
LALAL.AI is a next-generation vocal remover and music source separation service that offers fast, easy, and precise stem extraction. It allows users to remove vocals, instrumental tracks, drums, bass, guitar, and more without quality loss. The platform uses advanced AI technology to provide high-quality stem splitting based on transformer-based audio separation approach. Users can create custom voices, remove background noise, change voices, and separate lead and backing vocals with pinpoint accuracy. LALAL.AI offers various packages for individuals and businesses, with features like fast processing queue, batch upload, and stem download. The service supports a wide range of input/output formats for audio and video files.
Ermine.ai
Ermine.ai is an AI-powered tool for local audio recording and transcription. It allows users to transcribe audio files into text with high accuracy and efficiency. The tool is designed to work seamlessly with Chrome browser, with Firefox support coming soon. Users can easily transcribe audio files in English by allowing microphone access and initializing the transcription model. Ermine.ai provides a convenient solution for transcribing audio content for various purposes, such as meetings, interviews, lectures, and more.
Audiobox
Audiobox is an AI tool developed by Meta for audio generation. It allows users to create custom audio content by generating voices and sound effects using voice inputs and natural language text prompts. The tool includes various models such as Audiobox Speech and Audiobox Sound, all built upon the shared self-supervised model Audiobox SSL. Audiobox aims to make AI safe and accessible for everyone by providing a platform for creative audio storytelling and research in the field of audio generation.
AudioDiary
AudioDiary is a super-smart AI voice journal application that effortlessly transforms your fleeting thoughts into lasting insights. It allows users to record their thoughts, transcribes them, analyzes the content, and provides personalized goals and suggestions based on the user's entries. The app is available on iOS, Android, MacOS, and Web App Store, with high ratings and positive reviews from users. AudioDiary offers a unique and interactive way for users to journal using voice input, making it easier and more engaging for individuals to reflect on their day and set goals.
Ai-SPY
Ai-SPY is an advanced AI audio detection tool that helps users identify whether speech is human or AI-generated. It offers detailed reports, easy integration with API access, and expert human insights for accurate analysis. Ai-SPY leverages a proprietary neural network to provide unparalleled audio authenticity insights, making it a valuable tool for content verification and manipulation detection.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
Audo Studio
Audo Studio is an AI-powered audio cleaning tool that automatically removes background noise, enhances speech, and adjusts volume levels with a single click. It offers fast and easy audio cleaning, advanced noise removal, echo reduction, and auto volume adjustment. With over 25,000 users and 300,000+ audio hours cleaned, Audo Studio is a popular choice for podcasters, YouTubers, and content creators looking to improve sound quality effortlessly.
GoWhisper
GoWhisper is a privacy-first, cross-platform desktop application for local audio transcription. It allows users to transcribe audio files on their local machine without the need for monthly subscriptions. With support for multiple languages and file formats, GoWhisper offers a seamless audio-to-text conversion experience. The application is designed to cater to researchers, podcasters, content creators, journalists, small business owners, and legal professionals, providing a reliable and secure transcription solution.
Splitter.ai
Splitter.ai is an AI-driven audio processing platform developed by a Swedish research company. It offers advanced audio processing technologies, including stem separation/extraction, reverb removal, and direct YouTube splitting. The platform is designed to assist music producers, DJs, artists, forensics engineers, audio engineers, karaoke enthusiasts, police, scientists, and more in enhancing their audio processing tasks. Splitter.ai aims to provide high-quality services through AI-driven solutions to meet the diverse needs of its users.
Transkriptor
Transkriptor is an AI-powered tool that allows users to convert audio or video files into text with high accuracy and efficiency. It supports over 100 languages and offers features like automatic transcription, translation, rich export options, and collaboration tools. With state-of-the-art AI technology, Transkriptor simplifies the transcription process for various purposes such as meetings, interviews, lectures, and more. The platform ensures fast, accurate, and affordable transcription services, making it a valuable tool for professionals and students across different industries.
Samplab
Samplab is an AI-powered audio editing tool that allows users to manipulate audio samples with advanced features such as note editing, chord detection, stem separation, audio to MIDI conversion, and audio warping. It offers a seamless integration with digital audio workstations (DAWs) as a plugin or desktop app, enabling producers to enhance their music production workflow. Samplab's AI technology revolutionizes the way users interact with audio samples, providing unprecedented control over notes, chords, and melodies.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.

ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.
DIY Audio Guru
An assistant to help audio DIY'ers of any level, and anyone curios about audio to identify issues, find information, and general assistance in their journey.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.

Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.
ConvertAnything
The ultimate tool for converting files, whether they are images, audio, video, documents, or other types. It can process single files or multiple files in bulk, accepts ZIP files, and offers a download link [Updated version].
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
awesome-mcp-servers
A curated list of awesome Model Context Protocol (MCP) servers that enable AI models to securely interact with local and remote resources through standardized server implementations. The list focuses on production-ready and experimental servers extending AI capabilities through file access, database connections, API integrations, and other contextual services.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models

AITreasureBox
AITreasureBox is a comprehensive collection of AI tools and resources designed to simplify and accelerate the development of AI projects. It provides a wide range of pre-trained models, datasets, and utilities that can be easily integrated into various AI applications. With AITreasureBox, developers can quickly prototype, test, and deploy AI solutions without having to build everything from scratch. Whether you are working on computer vision, natural language processing, or reinforcement learning projects, AITreasureBox has something to offer for everyone. The repository is regularly updated with new tools and resources to keep up with the latest advancements in the field of artificial intelligence.
awesome-ai-tools
This repository contains a curated list of awesome AI tools that can be used for various machine learning and artificial intelligence projects. It includes tools for data preprocessing, model training, evaluation, and deployment. The list is regularly updated with new tools and resources to help developers and data scientists in their AI projects.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
Demucs-Gui
Demucs GUI is a graphical user interface for the music separation project Demucs. It aims to allow users without coding experience to easily separate tracks. The tool provides a user-friendly interface for running the Demucs project, which originally used the scientific library torch. The GUI simplifies the process of separating tracks and provides support for different platforms such as Windows, macOS, and Linux. Users can donate to support the development of new models for the project, and the tool has specific system requirements including minimum system versions and hardware specifications.
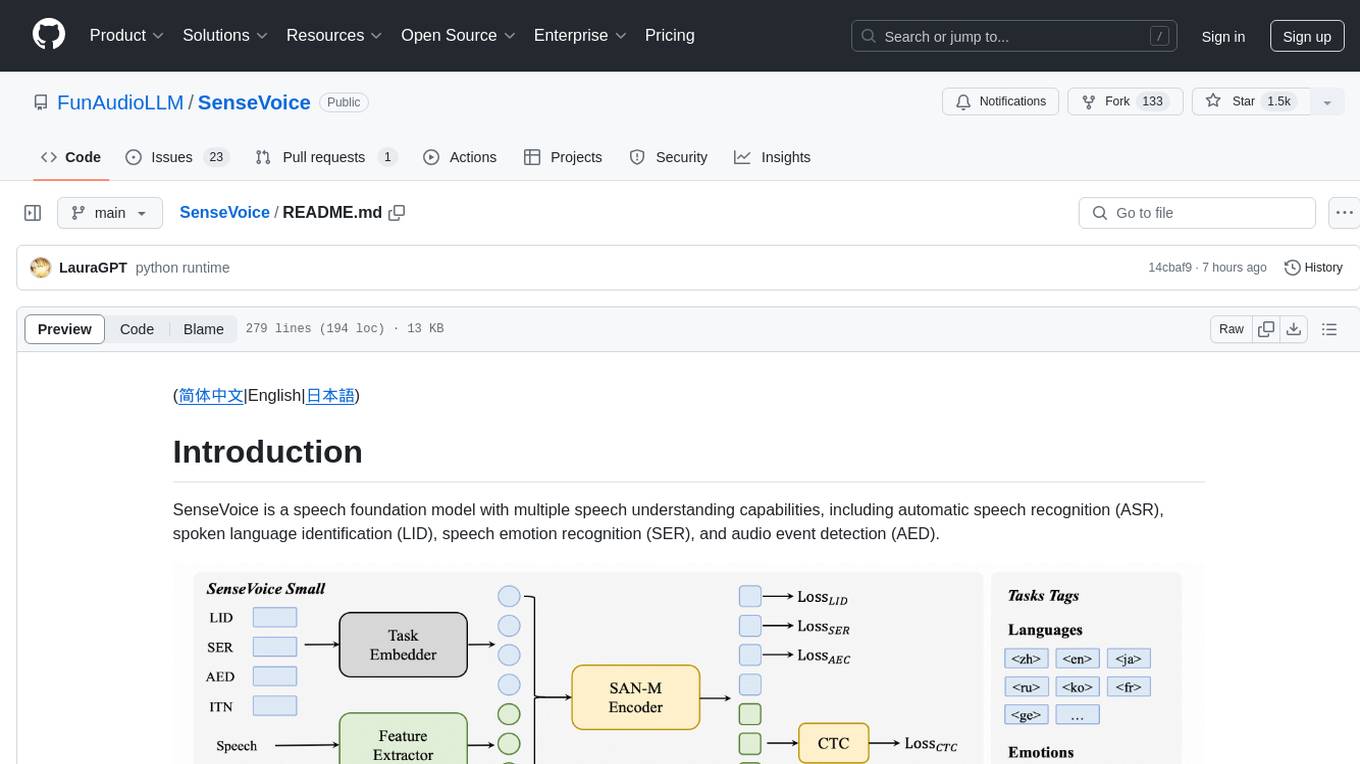
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

Apt
Apt. is a free and open-source AI productivity tool designed to enhance user productivity while ensuring privacy and data security. It offers efficient AI solutions such as built-in ChatGPT, batch image and video processing, and more. Key features include free and open-source code, privacy protection through local deployment, offline operation, no installation needed, and multi-language support. Integrated AI models cover ChatGPT for intelligent conversations, image processing features like super-resolution and color restoration, and video processing capabilities including super-resolution and frame interpolation. Future plans include integrating more AI models. The tool provides user guides and technical support via email and various platforms, with a user-friendly interface for easy navigation.

py-gpt
Py-GPT is a Python library that provides an easy-to-use interface for OpenAI's GPT-3 API. It allows users to interact with the powerful GPT-3 model for various natural language processing tasks. With Py-GPT, developers can quickly integrate GPT-3 capabilities into their applications, enabling them to generate text, answer questions, and more with just a few lines of code.
awesome-khmer-language
Awesome Khmer Language is a comprehensive collection of resources for the Khmer language, including tools, datasets, research papers, projects/models, blogs/slides, and miscellaneous items. It covers a wide range of topics related to Khmer language processing, such as character normalization, word segmentation, part-of-speech tagging, optical character recognition, text-to-speech, and more. The repository aims to support the development of natural language processing applications for the Khmer language by providing a diverse set of resources and tools for researchers and developers.

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.
CVPR2024-Papers-with-Code-Demo
This repository contains a collection of papers and code for the CVPR 2024 conference. The papers cover a wide range of topics in computer vision, including object detection, image segmentation, image generation, and video analysis. The code provides implementations of the algorithms described in the papers, making it easy for researchers and practitioners to reproduce the results and build upon the work of others. The repository is maintained by a team of researchers at the University of California, Berkeley.